Bridge Netfilter: Unexpected Consequences

Docker loads bridge netfilter kernel module which creates certain side effects on the system. This blog explores the unexpected consequences and provides a solution for it.
The problem
My journey into the bridge netfilter rabbit hole started when I was trying to create a network topology on my system using namespaces. A simplified version that showcases the core problem is as shown below:
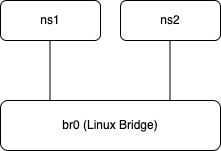
In this setup, there are two network namespaces connected via a linux bridge. The goal is to ping between them.
#!/bin/bash
# Create two network namespaces
ip netns add ns1
ip netns add ns2
# Create a bridge
ip link add br0 type bridge
ip link set dev br0 up
# Create two veth pairs
ip link add veth0a type veth peer name veth0b
ip link add veth1a type veth peer name veth1b
# Move one end of each veth pair into the namespaces
ip link set veth0a netns ns1
ip link set veth1a netns ns2
# Configure the interfaces in the namespaces
ip netns exec ns1 ip addr add 192.168.30.1/24 dev veth0a
ip netns exec ns1 ip link set dev veth0a up
ip netns exec ns1 ip link set dev lo up
ip netns exec ns2 ip addr add 192.168.30.2/24 dev veth1a
ip netns exec ns2 ip link set dev veth1a up
ip netns exec ns2 ip link set dev lo up
# Connect the other ends of the veth pairs to the bridge
ip link set veth0b master br0
ip link set veth1b master br0
# Enable the bridge interface
ip link set dev br0 up
echo "Network namespaces and bridge are set up."
The expectation here is that as both the namespaces are in the same subnet and connected to by a bridge, they should be able to ping each other. But surprisingly, the ping does not work.
ARP resolution
When checked, the arp resolution was successful on the namespaces showing that the Layer 2 is working well.
# arp -n
Address HWtype HWaddress Flags Mask Iface
192.168.30.2 ether 86:3a:ab:26:5c:97 C veth0a
IPTable rules
As this is pure Layer 2 communication, the effects of iptable rules were not considered. After exhausting all the troubleshooting options, I googled for this problem and found a very interesting concept around br-netfilter here
It turns out, if docker is installed on a system it enables br-netfilter kernel module and in addition it changes the default FORWARD chain policy to DROP.
INPUT ACCEPT
FORWARD DROP
OUTPUT ACCEPT
We can check if br-netfilter module is loaded using the below command:
# lsmod | grep -E 'veth|bridge'
veth 32768 0
bridge 307200 1 br_netfilter
stp 16384 1 bridge
llc 16384 2 bridge,stp
Loading the br-netfilter module will result in iptable rules being applied on bridged ethernet frames and will result in packet drops, which will be totally unexpected by the unaware.
Solution for the impatient
If you are looking for a quick solution to the problem, you need to add the below rule to your iptables:
sudo iptables -I FORWARD -i <bridge-name> -j LOG --log-prefix "ACCEPTED: " # remove this line if you don't want logging
sudo iptables -I FORWARD -i <bridge-name> -j ACCEPT
Understanding br-netfilters
As per the br-netfilter website, the module enables the following functionality:
- {Ip, Ip6, Arp}tables can filter bridged IPv4/IPv6/ARP packets, even when encapsulated in an 802.1Q VLAN or PPPoE header
This enables the functionality of a stateful transparent firewall.- All filtering, logging and NAT features of the 3 tools can therefore be used on bridged frames.
- Combined with ebtables, the bridge-nf code therefore makes Linux a very powerful transparent firewall.
- This enables, f.e., the creation of a transparent masquerading machine (i.e. all local hosts think they are directly connected to the Internet).
- Letting {ip, ip6, arp}tables see bridged traffic can be disabled or enabled using the appropriate proc entries, located in /proc/sys/net/bridge/:
- bridge-nf-call-arptables
- bridge-nf-call-iptables
- bridge-nf-call-ip6tables
- Also, letting the aforementioned firewall tools see bridged 802.1Q VLAN and PPPoE encapsulated packets can be disabled or enabled with a proc entry in the same directory:
- bridge-nf-filter-vlan-tagged
- bridge-nf-filter-pppoe-tagged These proc entries are just regular files. Writing ‘1’ to the file (echo 1 > file) enables the specific functionality, while > writing a ‘0’ to the file disables it.
An excerpt from here says:
If you have mod probe enabled and iptables Forward chain dropping packets:
iptables -I FORWARD -j DROP
modprobe br_netfilter
then by default the bridge will drop all IPv4 traffic received at layer 2 through iptables. For IPv4 frames, br_netfilter will temporarily “upgrade” Ethernet frames at layer 2 into IPv4 packets and feed them to iptables, still in the bridge path. Packets dropped by iptables won’t go out of the bridge. Those not dropped are fed back as Ethernet frames into the bridge to continue bridge processing.
Chain traversal for bridged IP packets
The following picture shows the chain traversal done by bridged ethernet frames/packets.

Here, the chains in green belong to netfilter which is used by IPTables. The chains in blue belong to bride-netfilter used by etables/nftables.
As can be seen, a bridged frame will hit 3 of the iptable chains:
- nat PREROUTING
- filter FORWARD
- nat POSTROUTING
Due to this reason, the iptable rules in these 3 chains apply to the bridged traffic and in our case filter FORWARD chain rules will drop the frames between ns1 and ns2.
Unexpected scenario
When the br-nf module is enabled in the kernel, a frame/packet can go through the above 3 mentioned iptable chains in two possible ways:
- The frame is bridged.
- The packet got routed.
So, the complexity comes in filter FORWARD chain where it needs to distinguish between these two flows.
Strange behavior starts to happen when this distinction is not provided. The below example picked up from etables.netfilter.org provides insights into the issue. I will explain it with my interpretation.
Lets say we have the below setup:
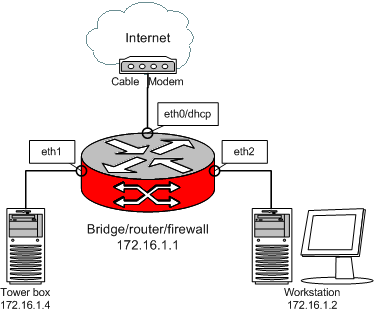
The bridge/router is connected to the internet via port eth0 and has the below rule set:
iptables -t nat -A POSTROUTING -s 172.16.1.0/24 -j MASQUERADE
The requirement here is that traffic between 172.16.1.2 and 172.16.1.4 is bridged, while the rest is routed, using masquerading.
Now at the filter FORWARD chain level, some distinction has to be made to make it understand which traffic is for routing and which is for bridging.
Lets say, we don’t add any rules and try to ping between 172.16.1.2 and 172.16.1.4. The bridge will receive the ping request and will send it to the other end after masquerading the src ip address. So when the packet is received by 172.16.1.4 the src ip will be 172.16.1.1 instead of 172.16.1.2. When 172.16.1.4 sends the response back to the bridge, masquerading will kick in again and change the ip destination of this response from 172.16.1.1 to 172.16.1.4. The ping will work and the end result will look as if everything is working fine but internally bridged frames are getting masqueraded.
To avoid this situation, we need to make filter FORWARD chain aware of the two possible packet flows, bridged vs routing. This can be done by adding the below rule (which is generally unnecessary if only iptables is being used) to the iptables.
iptables -A FORWARD -s 172.16.1.0/24 -d 172.16.1.0/24 -j ACCEPT
The etables.netfilter.org sets iptable rule on the POSTROUTING chain which I feel is a typo. I have corrected it to the FORWARD chain above.
iptables -t nat -A POSTROUTING -s 172.16.1.0/24 -d 172.16.1.0/24 -j ACCEPT
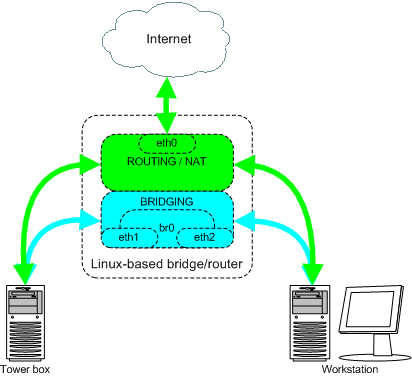
Lets complete the discussion with a high level overview diagram of packet flow in linux networking.
High level network packet flow

The Link Layer at the bottom (blue) is where bridging happens and the green chains in this layer indicate the iptable chains that get called in the bridging flow due to the br-nf module.
- bridge-netfilter
- ebtables/iptables interaction on a Linux-based bridge
- https://serverfault.com/questions/963759/docker-breaks-libvirt-bridge-network/964491#964491?newreg=8455ebf220c8457895cd2eafb8b7db91
- https://unix.stackexchange.com/questions/671644/cant-establish-communication-between-two-network-namespaces-using-bridge-networ